

The Inference Singularity
How Nvidia just bought the only technology capable of beating them.

Disclaimer: Not financial advice. Do your own research and due diligence. At the time of writing I am holding a position in NVIDIA.
Introduction
The semiconductor industry runs on two things: physics and supply chains. In late 2025, Nvidia mastered both to close the single most dangerous vulnerability in its defensive moat: inference efficiency.
I originally sat down to write a simple update on two acquisitions. But as I peeled back the layers of the SchedMD1 and Groq2 deals, I actually stopped typing. I realized I was looking at something much bigger than a standard merger. And that both transactions were actually highly predictable, just from following the news345 in the tech space and NVIDIA’s latest investor relations slide deck.6
The transformation of NVIDIA has been meticulously shaped not only by insane engineering of talented people, but by targeted acquisitions. To understand why the most recent two deals were truly historic (and what they mean for the future of semiconductors) I have laid out the analysis below.
(btw: this is not meant as an in-depth quantitative analysis, but rather as a fundamental analysis to lay the foundation of a better understanding of NVIDIA’s true moat)
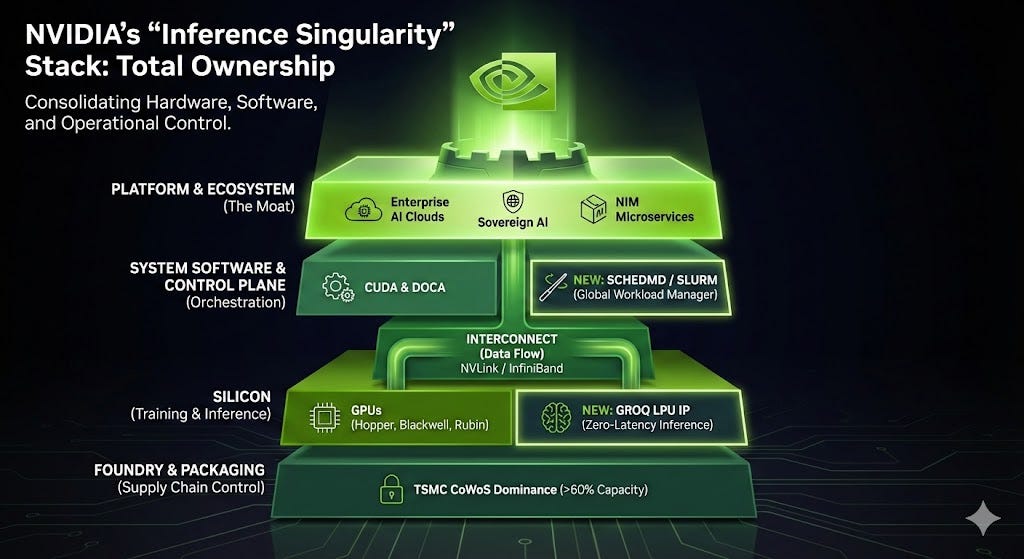
Executive summary
For years, the bear case against Nvidia was simple: Training is a GPU monopoly, but inference (running the models) will belong to cheaper, specialized chips like Google’s TPU.
“Anthropic’s choice to significantly expand its usage of TPUs reflects the strong price-performance and efficiency its teams have seen with TPUs for several years,” said Thomas Kurian, CEO at Google Cloud.7
The thesis was that hyperscalers would flood the market with “Inference-as-a-Service” at $0.50 per million tokens, undercutting Nvidia’s $2.00 premium.89
I used to believe that thesis. But looking at these supply chain numbers, I have to say: That thesis is dead.
Through a surgical $20B transaction with Groq10 and a ruthless cornering of manufacturing capacity that forced Google to slash production targets, Nvidia has effectively captured the future of inference.
This is what I call the “Inference Singularity”: the exact moment when the AI hardware market consolidated into a unified, industrial regime.
1. The Deal: Regulatory Jiu-Jitsu
On Christmas Eve 2025, Nvidia announced a $20 billion “non-exclusive licensing agreement” with Groq, the pioneer of ultra-low-latency inference.11
Do not be fooled by the phrasing. This was a de facto acquisition designed to bypass antitrust gridlock.
The asset: Nvidia gains full access to Groq’s LPU (Language Processing Unit) architecture.
The talent: Nvidia hired Groq founder Jonathan Ross (the creator of Google’s TPU) and ~90% of the engineering staff.
The fiction: By leaving the corporate entity of Groq alive to “license” IP to others, Nvidia avoids the immediate blocks that killed its Arm acquisition, while effectively absorbing the brain trust that made the technology work.
2. The Tech: Why the LPU is a “GPU Killer”
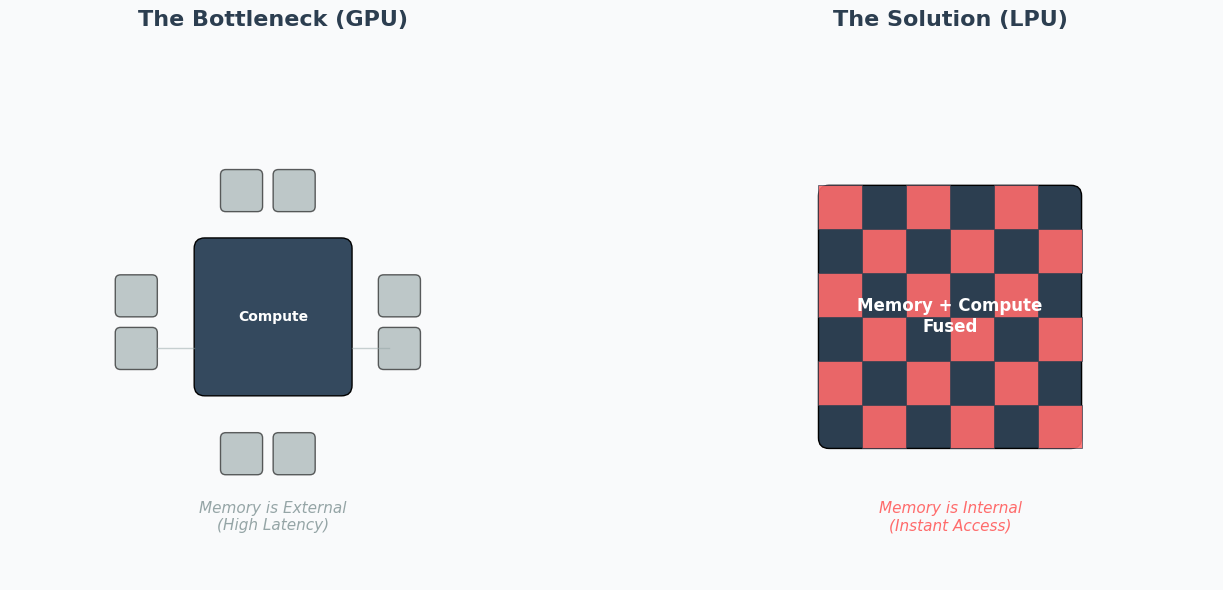
Why pay $20 billion for a license? Because the GPU architecture has a fundamental flaw when it comes to reasoning.
The GPU problem (probabilistic): GPUs (like the H100) are throughput engines. They rely on HBM (high bandwidth memory) to store massive models. But HBM is physically far from the compute cores. When a GPU generates text token-by-token, the compute cores often sit idle, waiting for data. This creates latency and wastes power—the “Memory Wall.”
The LPU solution (deterministic): Groq’s LPU removes the HBM entirely. It relies on massive amounts of on-chip SRAM (static random-access memory), which is 1-100x faster. Crucially, it is deterministic: the compiler plans every electron movement before the chip turns on.12
The result: Instant latency. By absorbing this, Nvidia can now integrate SRAM-heavy “inference tiles” into its future Rubin architecture.
Crucial caveat: This integration is a massive engineering hurdle. Groq’s SRAM-based design is physically distinct from Nvidia’s HBM-centric layout. I think we should expect a 18-24 month integration timeline before we finally see “Groq-inside” silicon on the market. This is a long-term play, not an overnight patch.
3. The Supply Chain “Strangulation”
While Nvidia was buying the technology, physics was strangling the competition.
Reports confirm that Google has cut its 2026 TPU production target significantly, potentially from ~4 million to ~3 million units.13
The cause: The bottleneck is CoWoS (Chip-on-Wafer-on-Substrate) packaging at TSMC—the advanced glue that holds modern AI chips together.
The move: Nvidia aggressively booked over 60% of TSMC’s global CoWoS capacity for its own Blackwell and Rubin chips.
The impact: Google does not have enough capacity to build TPUs for the wider market. The units they can build will be consumed entirely by internal demand (Search, YouTube, Gemini training).
This kills the commercial threat. Google cannot flood the market with cheap inference chips because they literally cannot manufacture them fast enough.
But, that might actually be set to change beyond 2026, when Google plans to aggressively scale production, targeting approximately 5 million units in 2027 and rising to 7 million in 2028. This expansion centers on the eighth-generation TPU (v8), which is scheduled for mass production on TSMC’s 3nm node starting in the second half of 2026. To support this volume, Google is diversifying its supply chain by partnering with both Broadcom (for high-performance training chips) and MediaTek (for volume-focused inference chips).14
4. The Moat: Owning the “Control Plane”
While the hardware war grabbed headlines, Nvidia quietly secured the software layer by acquiring SchedMD, the stewards of Slurm.
Slurm is the workload manager that runs 60% of the world’s supercomputers. By owning it, Nvidia now controls the “traffic controller” of the AI data center.
The Real Lock-in: Slurm itself is open source (GPL). However, the true value lies in the proprietary plugins for NVLink interconnects and enterprise support contracts. Nvidia can now optimize Slurm to prioritize their own hardware extensions, creating a “soft lock-in” where enterprise clusters simply run better, faster, and more reliably on Green Team silicon.
5. The Master Plan: A History of Strategic Layering
When you step back, you realize the SchedMD and Groq deals aren’t isolated events. They are the final capstones of a six-year strategy to own every layer of the “AI Factory.” Nvidia isn’t just selling the car; they bought the road, the traffic lights, and the mechanic.

Here is their “shopping list” that built the monopoly:
2019 - Mellanox ($6.9B):
The “Plumbing.” This gave Nvidia ownership of InfiniBand, the high-speed networking cables that allow thousands of GPUs to talk to each other instantly. Without this, a GPU cluster is just a pile of isolated chips.152023 - OmniML & 2024 - Deci ($300M+):16
The “Compression.” These acquisitions gave Nvidia the algorithms to shrink models so they run faster on Nvidia hardware. This is the engine behind NIMs (Nvidia Inference Microservices).2024 - Run:ai (~$700M):17
The “Virtualization.” Run:ai builds software to split one GPU into multiple smaller virtual GPUs. This secured Nvidia’s grip on the Kubernetes layer, ensuring cloud-native apps run best on Green hardware.2024 - Shoreline ($100M):18
The “Mechanic.” This deal gave Nvidia automated incident response software. When a GPU cluster crashes, Shoreline fixes it. It turns Nvidia from a hardware vendor into an operational utility.2025: SchedMD and Groq19
The Synthesis: By adding SchedMD (Scheduling) and Groq (Inference) to this list, Nvidia has closed the loop. They now control the hardware, the network, the virtualization, the scheduling, and the maintenance.
6. The Highly Predictable Deals
Upon further reflection I believe that these deals aren’t only very smart and business savvy for different strategic reasons. They are essentially just a continuation or maybe the grand finale of Jensen’s master plan for transforming the green giant into what they already called an AI infrastructure company several times and repeated saying in their latest investor relations’ material back in October 2025.
Analyzing the October 2025 IR deck20 in the context of Google’s TPU aggression21 reveals that these deals were not random, but necessary moves to close specific moats where NVIDIA was vulnerable to Google’s vertically integrated stack.
Here is my critical assessment:
6.1. The SchedMD Deal: Highly Anticipatable (The “Sovereign Cloud” Moat)
The acquisition of SchedMD (the commercial entity behind Slurm) was the missing piece explicitly demanded by NVIDIA’s strategy in the deck. All references in section 6.1 relate to pages of the aforementioned October 2025 IR slide deck
The Google threat: Google’s competitive advantage isn’t just the TPU; it is Borg (their proprietary cluster scheduler). Borg allows Google to run TPUs at massive efficiency, handling job failures and resource allocation seamlessly. It operates at massive scale, managing hundreds of thousands of jobs from thousands of applications across many clusters, each containing up to tens of thousands of machines.22 NVIDIA sells chips to “sovereign” entities (slide 14 mentions “OpenAI, Microsoft, OCI, CoreWeave”), but these partners lack a unified, battle-tested scheduler for supercomputing scale.
The deck’s signal:
“AI Infrastructure Company”: Slide 3 explicitly rebrands NVIDIA from a chip company to an “AI Infrastructure Company.”
Scale of operations: Slide 14 outlines a “10 Gigawatt” build-out with OpenAI. Managing 10GW of GPU compute is impossible with standard enterprise tools (like basic Kubernetes). It requires HPC-grade scheduling.
Supercomputer DNA: Slide 3 highlights the “AI Supercomputer.” Slurm is the standard workload manager for the world’s top supercomputers. To sell “AI Factories” (Slide 14) that rival Google’s efficiency, NVIDIA had to own the software layer that controls them.
Conclusion: NVIDIA could not risk the software layer of its 10GW deployment being a bottleneck. Buying SchedMD was the only way to guarantee their hardware (”Blackwell,” “Rubin”) would actually be utilizable at the scale promised in the deck.
6.2. The Groq Deal: Anticipatable as Defense (The “Inference” Moat)
The deck suggests NVIDIA dominates inference, but in my opinion the intensity of that claim reveals their anxiety about it, making the Groq move a logical consolidation of talent/IP.
The Google Threat: By late 2025, Google’s TPUs (likely v6/Ironwood) were aggressively marketing inference cost-efficiency (cheaper/token) rather than just training speed.23 Inference is where the money is (serving users), and TPUs are historically more cost-efficient here than GPUs.
The Deck’s Signal:
Inference anxiety: Slide 13 is entirely devoted to proving “15X TPS/GPU vs H200.” This is a defensive slide. If NVIDIA were truly unchallenged, they wouldn’t need to model “TPS per User” vs “TPS per GPU” so granularly.
The “token” explosion: Slide 6 notes “Token generation is doubling every two months.” This exponential demand for inference (not just training) meant NVIDIA couldn’t rely solely on raw power; they needed architectural efficiency.
The deal logic: Groq’s LPU architecture was built purely for inference speed (latency/throughput).
Critical assessment: The deck claims NVIDIA solved the inference problem with GB200 (slide 13). However, the deal (hiring Groq’s team and licensing tech for ~$20B) is an admission that silicon alone wasn’t enough. To prevent Google from winning the “cost-per-token” war, NVIDIA needed to take the strongest alternative architecture (Groq) off the board and absorb its “inference-first” DNA.
Summary
I’d conclude here that the referenced IR deck paints a picture of a company shifting from selling components to selling the entire factory.
Google’s push proved that “chips” are commoditized; the value is in the integrated system (TPU + Borg).
NVIDIA’s response (the deals) was to buy the components of that integrated system: SchedMD gave them the “Borg” equivalent (Slurm), and Groq gave them the specialized “inference” IP to protect their flank against cost-optimized TPUs.
Therefore, the deals were a direct execution of the “AI Infrastructure” strategy outlined on slide 3.
7. Conclusion & Outlook (2026-2030)
7.1 Does the Groq Deal Kill the TPU Threat?
My verdict: I believe it neutralizes the existential threat, but the TPU remains a persistent economic rival.
The Groq deal “kills” the technical argument that GPUs are unfit for inference. However, the TPU threat is not dead because of Google’s sheer scale.
Facing the TSMC bottleneck, reports confirm Google has been forced into the arms of Samsung foundry, initiating a high-stakes gamble on Samsung’s manufacturing process for its future TPU generations.24 This is a double-edged sword: while it secures capacity, Samsung has historically struggled with yield rates on advanced nodes compared to TSMC. Google is trading capacity certainty for yield risk. If Samsung’s yields falter, Google’s cost advantage could evaporate overnight.
7.2 Final Thoughts
NVIDIA’s recent moves demonstrate a profound understanding of the Innovator’s Dilemma. Rather than waiting for a disruption (cheap inference ASICs) to kill their high-margin business, they aggressively co-opted the disruption (Groq) and locked down the control points (SchedMD).
We often talk about “moats” in business as abstract concepts. But seeing Nvidia lock down the physics of the chip and the logic of the scheduler simultaneously? That isn’t just a moat. That is a fortress.
The “Inference Singularity” has arrived.
Source: Sand2Server
Outlook
If there is interest, please let me know and I could plan a deep dive on Language Processing Units (LPUs), an architecture designed from first principles to solve the specific bottlenecks of large language model inference
I am also working on several posts, including
Uber being massively misunderstood
Aixtron’s monopolistic revenue potential
Why Marvell might be a sleeping giant
Hard questions
Ubiquityof code
WFE industry primer
AI governance
and so much more in my topic backlog … (This will already take several weeks for me to work through)
Disclaimer: The content shared on Sand2Server is for informational and educational purposes only and should not be considered financial advice. Again - please do your own research before making any investment decisions.
References
NVIDIA Acquires Open-Source Workload Management Provider SchedMD - NVIDIA will continue to distribute SchedMD’s open-source, vendor-neutral Slurm software, ensuring wide availability for high-performance computing and AI (NVIDIA newsroom): https://blogs.nvidia.com/blog/nvidia-acquires-schedmd/ [Accessed at: 01/07/2026]
Groq and Nvidia Enter Non-Exclusive Inference Technology Licensing Agreement to Accelerate AI Inference at Global Scale (Groq newsroom): https://groq.com/newsroom/groq-and-nvidia-enter-non-exclusive-inference-technology-licensing-agreement-to-accelerate-ai-inference-at-global-scale [Accessed at: 12/24/2025]
Exclusive: Google works to erode Nvidia’s software advantage with Meta’s help (Reuters): https://www.reuters.com/business/google-works-erode-nvidias-software-advantage-with-metas-help-2025-12-17/ [Accessed at: 12/17/2025]
3 things to know about Ironwood, our latest TPU (Google Blog): https://blog.google/innovation-and-ai/infrastructure-and-cloud/google-cloud/ironwood-google-tpu-things-to-know/ [Accessed at: 12/29/2025]
Expanding our use of Google Cloud TPUs and Services (Anthropic newsroom): https://www.anthropic.com/news/expanding-our-use-of-google-cloud-tpus-and-services [Accessed at: 12/29/2025]
NVIDIA Investor relations - Non-Deal Roadshow (October 2025): https://s201.q4cdn.com/141608511/files/doc_presentations/2025/10/NVIDIA-2025-NDR-Deck-1.pdf [Accessed at: 01/03/2026]
Expanding our use of Google Cloud TPUs and Services (Anthropic newsroom): Quote from https://www.anthropic.com/news/expanding-our-use-of-google-cloud-tpus-and-services [Accessed at: 12/29/2025]
Ultimate Guide: The Best Cheapest Inference Services of 2025 (SiliconFlow): https://www.siliconflow.com/articles/en/the-cheapest-LLM-models [Accessed at: 01/03/2026]
Google TPU v6e vs GPU: 4x Better AI Performance Per Dollar Guide (Introl): https://introl.com/blog/google-tpu-v6e-vs-gpu-4x-better-ai-performance-per-dollar-guide [Accessed at: 01/03/2026]
See 2.
See 2.
Inside the LPU: Deconstructing Groq’s Speed (Groq): https://groq.com/blog/inside-the-lpu-deconstructing-groq-speed [Accessed at: 01/08/2026]
Expanding TPU Production Could Bring Alphabet Billions in New Revenue, Says Morgan Stanley (Investorshub): https://investorshub.advfn.com/market-news/article/20708/expanding-tpu-production-could-bring-alphabet-billions-in-new-revenue-says-morgan-stanley#:~:text=Morgan%20Stanley’s%20Asia%20semiconductor%20team,for%20much%20broader%20TPU%20deployment. [Accessed at: 01/08/2026]
Google Led TPU Innovation with Patent Spike; Broadcom, MediaTek Reportedly Boost Reserved Wafers (TrendForce): https://www.trendforce.com/news/2026/01/05/news-google-led-tpu-innovation-with-patent-spike-broadcom-mediatek-reportedly-boost-reserved-wafers/ [Accessed at: 01/08/2026]
NVIDIA to Acquire Mellanox for $6.9 Billion (NVIDIA newsroom:): https://nvidianews.nvidia.com/news/nvidia-to-acquire-mellanox-for-6-9-billion [Accessed at: 01/08/2026]
Nvidia acquires OmniML for AI Edge workloads - Quietly picked up the startup early this year (DataCenterDynamics /DCD): https://www.datacenterdynamics.com/en/news/nvidia-acquires-omniml-for-ai-edge-workloads/ [Accessed at: 01/08/2026]
Nvidia to acquire AI startup Deci for $300 million (Ctech): https://www.calcalistech.com/ctechnews/article/bkj6phggr [Accessed at: 01/08/2026]
M&A News: Nvidia Eyes Shoreline.io for $100M (NASDAQ): https://www.nasdaq.com/articles/ma-news-nvidia-eyes-shorelineio-100m [Accessed at: 01/08/2026]
See 1 and 2.
NVIDIA Investor relations - Non-Deal Roadshow (October 2025); p. 3: https://s201.q4cdn.com/141608511/files/doc_presentations/2025/10/NVIDIA-2025-NDR-Deck-1.pdf [Accessed at: 01/03/2026]
Ironwood: The first Google TPU for the age of inference (Google Blog): https://blog.google/innovation-and-ai/infrastructure-and-cloud/google-cloud/ironwood-tpu-age-of-inference/ [Accessed at: 01/07/2026]
Large-scale cluster management at Google with Borg: errata 2015-04-23 https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/43438.pdf [Accessed at: 01/07/2026]
See 9.
Samsung Set to Benefit from TSMC’s ‘N-2’ Rule as AMD, Google Reportedly Eye U.S. 2nm Production (TrendForce): https://www.trendforce.com/news/2025/12/23/news-samsung-set-to-benefit-from-tsmcs-n-2-rule-as-amd-google-reportedly-eye-u-s-2nm-production/ [Accessed at: 01/09/2026]
Thank You.
This was fantastic, thx!